语言云使用文档
关于使用多种编程语言调用语言云服务
注册及下载
为给LTP的用户提供更优质的服务质量,我们目前已经将所有服务部署到【讯飞开放平台】,大家可以点击链接进行免费使用,具体使用方式也请参考讯飞平台文档。之前 api.ltp-cloud.com 的接口也会在近期停止服务,希望大家能够尽快完成迁移工作。我们的demo系统将会持续保留,我们的最新进展也会先部署到demo展示,欢迎大家继续使用,测试后会部署到讯飞开放平台提供调用接口。
在使用语言云服务前,请注册一个账号。 按要求正确填写信息后,系统会向您的注册邮箱中发送一个token。 email:token将作为你调用语言云服务的认证。
然后下载最新版语言云SDK,选择相应的编程语言,并将email:token填入相应的认证函数中。 下面的文档会更加详细地介绍SDK的使用方法。
原理
在语言云中,客户端与服务器之间采用HTTP协议通信。客户端以POST方式提交数据到服务器,服务器将数据以XML的方式返回给客户端。
客户端在提交数据时,首先需要在HTTP请求头部中添加用户名密码以做验证。
客户端提交的POST请求主要有以下几个字段。
| 字段名 | 含义 |
|---|---|
| s | 输入字符串(注:UTF8编码) |
| x | 用以指明输入字符串是否是XML格式,在XML选项x为n的时候,代表输入原始句子;为y时代表输入XML格式 |
| t | 用以指明分析任务,t可以为分词(ws),词性标注(pos),命名实体识别(ner),依存句法分析(dp),语义角色标注(srl)或者全部任务(all) |
数据表示
LTP 数据表示标准称为LTML。下图是LTML的一个简单例子:
<?xml version="1.0" encoding="utf-8" ?>
<xml4nlp>
<note sent="y" word="y" pos="y" ne="y" parser="y" wsd="y" srl="y" />
<doc>
<para id="0">
<sent id="0" cont="我们都是中国人">
<word id="0" cont="我们" pos="r" ne="O" parent="2" relate="SBV" />
<word id="1" cont="都" pos="d" ne="O" parent="2" relate="ADV" />
<word id="2" cont="是" pos="v" ne="O" parent="-1" relate="HED">
<arg id="0" type="A0" beg="0" end="0" />
<arg id="1" type="AM-ADV" beg="1" end="1" />
</word>
<word id="3" cont="中国" pos="ns" ne="S-Ns" parent="4" relate="ATT" />
<word id="4" cont="人" pos="n" ne="O" parent="2" relate="VOB" />
</sent>
</para>
</doc>
</xml4nlp>LTML 标准要求如下:结点标签分别为 xml4nlp, note, doc, para, sent, word, arg 共七种结点标签:
-
xml4nlp为根结点,无任何属性值; -
note为标记结点,具有的属性分别为:sent,word,pos,ne,parser,srl;分别代表分句,分词,词性标注,命名实体识别,依存句法分析,词义消歧,语义角色标注;值为"n",表明未做,值为"y"则表示完成,如pos="y",表示已经完成了词性标注; -
doc为篇章结点,以段落为单位包含文本内容;无任何属性值; -
para为段落结点,需含id 属性,其值从0 开始; -
sent为句子结点,需含属性为id,cont;id 为段落中句子序号,其值从0 开始;cont 为句子内容; -
word为分词结点,需含属性为id, cont;id 为句子中的词的序号,其值从0 开始,cont为分词内容;可选属性为pos,ne,parent,relate;pos的内容为词性标注内容;ne为命名实体内容;parent与relate成对出现,parent为依存句法分析的父亲结点id 号,relate为相对应的关系; -
arg为语义角色信息结点,任何一个谓词都会带有若干个该结点;其属性为id,type,beg,end;id为序号,从0 开始;type代表角色名称;beg为开始的词序号,end为结束的序号;
各结点及属性的逻辑关系说明如下:
- 各结点层次关系可以从图中清楚获得,凡带有id 属性的结点是可以包含多个;
- 如果
sent="n"即未完成分句,则不应包含sent 及其下结点; - 如果
sent="y"word="n"即完成分句,未完成分词,则不应包含word 及其下结点; - 其它情况均是在
sent="y"word="y"的情况下:- 如果
pos="y"则分词结点中必须包含pos 属性; - 如果
ne="y"则分词结点中必须包含ne 属性; - 如果
parser="y"则分词结点中必须包含parent 及relate 属性; - 如果
srl="y"则凡是谓词(predicate)的分词会包含若干个arg 结点;
- 如果
Java
编译
编译LTPService.jar
为了使用Java版的SDK,首先需要编译LTPService.jar。 LTPService.jar使用ant编译工具编译。 在命令行环境下,可以在项目根目录下使用
ant命令直接编译。 编译成功后,将在build/jar下产生名为LTPService.jar的jar文件。
如果使用Eclipse,可以按照"File > New > Project... > Java Project from Existing Ant Buildfile"的方式从build.xml中创建项目。 选择next后,在Ant buildfile:一栏中填入build.xml的路径。 这里假设项目路径为E:\work\projects\ltp-cloud-sdk\JAVA。 build.xml的路径就是E:\work\projects\ltp-cloud-sdk\JAVA\build.xml
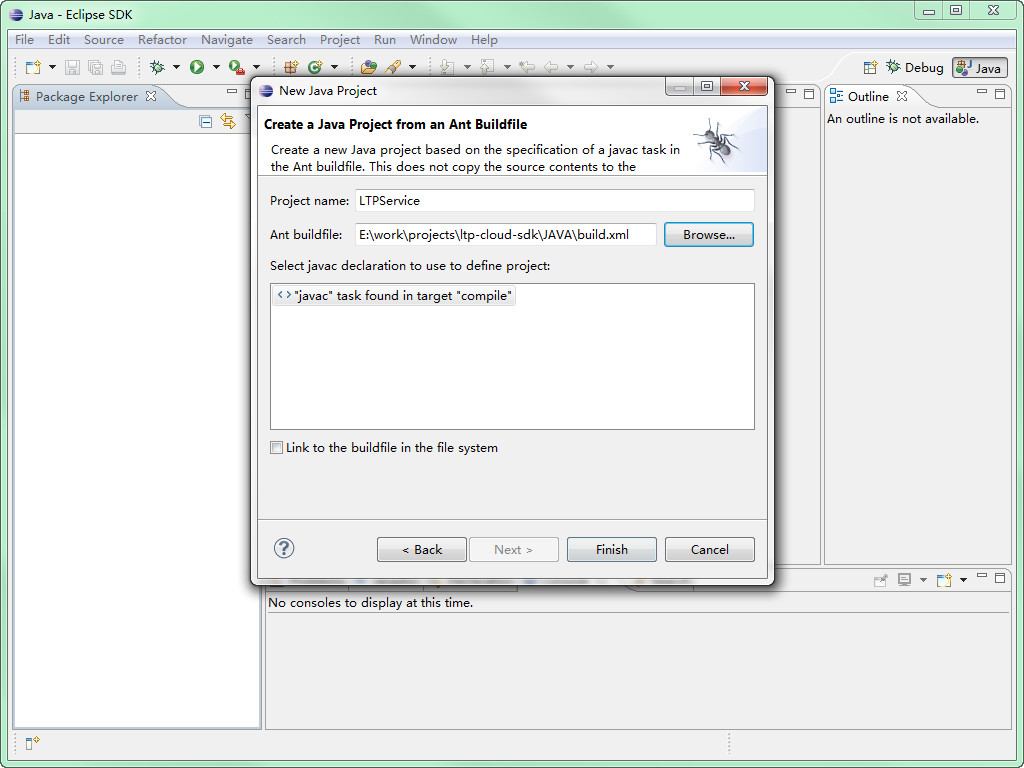
eclipse导入项目
点击Finish就导入了项目。
在导入项目后,右键build.xml选择2 Ant Build。 在弹出的对话框中的选择main选项卡,并在Base Directory:中填入项目路径。 在本例子里,需要填入E:\work\projects\ltp-cloud-sdk\JAVA。
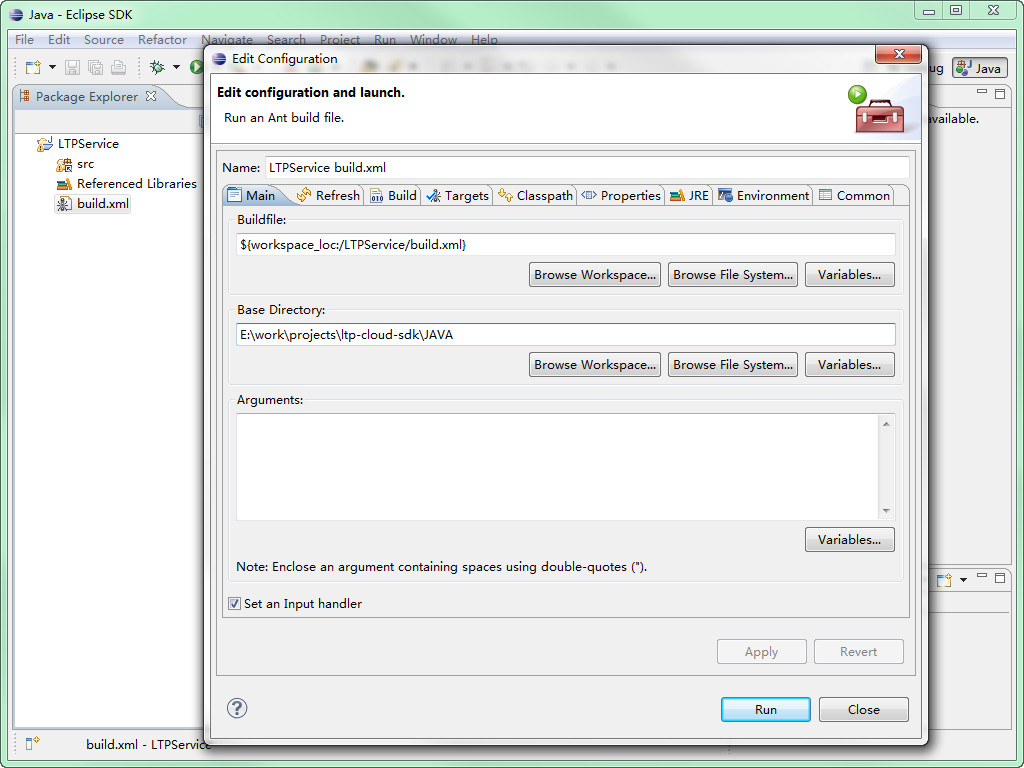
编译
填好后执行run,build/jar下产生名为LTPService.jar的jar文件。
编译运行Example
在编译获得LTPService.jar后,可以使用LTPService.jar编写调用语言云的程序。 在项目源码examples文件夹中,有编程样例(Example1.java,Example2.java,Example3.java)。 下面介绍如何编译样例。
如果在命令行环境下,可以使用
javac -cp ".:build/jar/LTPService.jar:lib/*" examples/Example3.java
java -cp ".:examples/:build/jar/LTPService.jar:lib/*:" Example3
如果需要使用Eclipse编译,可以在Properties > Java Build Path > Libraries > Add External JARs..中, 将LTPService.jar、commons-codec-1.4.jar、commons-logging.jar、httpclient-4.0.jar、httpcore-4.0.1.jar、jdom.jar几个Jar加入工程,就可以编译了。
接口文档
LTPService类
于edu.hit.ir.ltpService.LTPService 该类主要负责与服务器交互,并将返回结果以Ltml对象返回。
LTPService
- 功能:构造函数,初始化用户信息
- 参数:
参数名 参数描述 String authorization 用户验证信息,信息格式为:"email:token"
LTML Analyze
- 功能:发送LTML类型待分析信息,得到服务器分析结果。也可以根据自己的需求完成部分中文信息处理,保存在LTML类里,让服务器帮你完成其他任务。
- 参数:
参数名 参数描述 String option 分析方式,分析的方式LTPOption.xxx。可参阅LTPOption类 LTML ltmlIn 待分析的信息,为LTML类 - 返回值:返回分析结果,为一个LTML类
LTML类
位于edu.hit.ir.ltpService.LTML 该类是对返回的数据(xml)进行解析的主要对象。
ArrayList<Word> getWords
- 功能:提取LTML分析结果。
- 参数:
参数名 参数描述 int paragraphId 选择提取的段落序号 int sentenceIdx 选择提取的句子序号 - 返回值:提取的LTML分析结果。
String getSentenceContent
- 功能:提取分句结果。
- 参数:
参数名 参数描述 int paragraphIdx 选择提取的段落号针 int sentenceIdx 选择提取的句子号 - 返回值:提取的分句结果
以下几个方法是向LTML对象写数据的方法。注意以下几个问题:
- 请保证调用以下方法的LTML对象为空的,或首先调用过ClearDOM方法,以保证LTML对象中数据一致;
- 输入的数据必须保证一致,例如,如果第一个词完成了词性标注,则其余词也须完成词性标注,因为LTML对象是根据第一个词或第一句话生成的note结点;
已经调用SetOver的LTML对象不允许调用以下方法,否则会抛异常;凡是由LTPService对象返回的Ltml对象都调用过SetOver方法;
void addSentence
- 功能:在LTML中写入句子。输入完成部分分析的单词序列。
- 参数:
参数名 参数描述 ArrayList<Word> wordList 插入的组成句子的单词序列。其中note结点是根据第一个sentence第一个词生成的,必须保证后面句子中的词与第一个词一致,否则会抛异常。 int paragraphId 选择插入句子的段落号
void addSentence
- 功能:在LTML中写入句子。输入尚未做分词的字串
- 参数:
参数名 参数描述 String sentenceContent 插入的组成句子字串。 int paragraphId 选择插入句子的段落号
Word
该类型是对XML的Element进行的封装,任何的分析结果必须先取到Word,才能取到相当相应的分析数据。
| 函数名 | 返回值 |
|---|---|
| String getWS() | 返回词的具体内容。失败时返回空 |
| int getID() | 返回词的ID号 |
| String getPOS() | 返回词的词性标注。失败时返回空 |
| String getNE() | 返回词的命名实体识别结果。失败时返回空 |
| int getParserParent() | 返回词义消歧的解释。失败时返回空依存句法分析的父亲结点ID号,结返回结果为一个大于等于-2(>= -2)的整数,失败时返回-3 |
| bool isPredicate() | 检查该词是否是谓词。是返回true,否则返回false。 |
| ArrayList<SRL> getSRLs () | 如果该词是谓词;返回SRL类型的List |
SRL
SRL类型是对语义角色标注结果的一种抽象,主要包括语义角色标注类型(结果),开始词的ID号及结束词的ID号
| 选项名 | 含义述 |
|---|---|
| SRL.type | 公有String类型,语义角色标注类型(结果) |
| SRL.beg | 公有int类型,开始词的ID号 |
| SRL.end | 公有int类型,结束词的ID号 |
LTPOption
作为全局常量定义了分析方式类型
| 选项名 | 含义述 |
|---|---|
| LTPOption.WS | 分词 |
| LTPOption.POS | 词性标注 |
| LTPOption. NE | 命名实体识别 |
| LTPOption. PARSER | 依存句法分析 |
| LTPOption.SRL | 语义角色标注 |
示例程序
例一
发送string类型的分析对象,得到分析结果。并将结果按分词、ID、词性、命名实体、依存关系、词义消歧、语义角色标注的顺序输出。
public static void main(String[] args) {
LTPService ls = new LTPService("email:token");
try {
LTML ltml = ls.analyze(LTPOption.ALL,"我爱北京天安门。");
int sentNum = ltml.countSentence();
for(int i = 0; i < sentNum; ++i){
// 逐句访问
ArrayList < Word > wordList = ltml.getWords(i);
System.out.println(ltml.getSentenceContent(i));
for(int j = 0; j < wordList.size(); ++j){
System.out.print("\t" + wordList.get(j).getWS());
System.out.print("\t" + wordList.get(j).getPOS());
System.out.print("\t" + wordList.get(j).getNE());
System.out.print("\t" + wordList.get(j).getParserParent() + "\t" + wordList.get(j).getParserRelation());
// 如果是谓词则输出
if(ltml.hasSRL() && wordList.get(j).isPredicate()){
ArrayList < SRL > srls = wordList.get(j).getSRLs();
System.out.println();
for(int k = 0; k < srls.size(); ++k){
System.out.println("\t\t" + srls.get(k).type + "\t" + srls.get(k).beg + "\t" + srls.get(k).end);
}
}
System.out.println();
}
}
} catch (Exception e) {
e.printStackTrace();
}
}该用例首先实例化一个新的Service Client对象,用户名和密码被保存在这个对象中。然后,client发起一个请求,并指明分析目标位分词。请求结果返回并保存在一个LTML对象中。
例二
将待分析数据保存在LTML类中,发送LTML类型的分析对象得到分析结果。用例首先进行分词,将所得的词按用户词表进行合并或拆分,并对其进行依存句法分析。 本例中将“午夜”与“巴赛罗那”进行了合并。
public static void main(String[] args) {
LTPService ls = new LTPService("email:token");
try {
LTML ltmlBeg = ls.analyze(LTPOption.WS,"午夜巴塞罗那是对爱情的一次诙谐、充满智慧、独具匠心的冥想。");
LTML ltmlSec = new LTML();
int sentNum = ltmlBeg.countSentence();
for(int i = 0; i < sentNum; ++i){
ArrayList wordList = ltmlBeg.getWords(i);
for(int j = 0; j < wordList.size(); ++j){
System.out.print("\t" + wordList.get(j).getID());
System.out.print("\t" + wordList.get(j).getWS());
System.out.println();
}
// merge
ArrayList<Word< mergeList = new ArrayList<Word<();
Word mergeWord = new Word();
mergeWord.setWS(wordList.get(0).getWS()+wordList.get(1).getWS());
mergeList.add(mergeWord);
for(int j = 2; j < wordList.size(); ++j){
Word others = new Word();
others.setWS(wordList.get(j).getWS());
mergeList.add(others);
}
ltmlSec.addSentence(mergeList, 0);
}
ltmlSec.setOver();
System.out.println("\nmerge and get parser results.");
LTML ltmlOut = ls.analyze(LTPOption.PARSER, ltmlSec);
for(int i = 0; i < sentNum; ++i) {
ArrayList wordList = ltmlOut.getWords(i);
for(int j = 0; j < wordList.size(); ++j){
System.out.print("\t" + wordList.get(j).getID());
System.out.print("\t" + wordList.get(j).getWS());
System.out.print("\t" + wordList.get(j).getPOS());
System.out.print("\t" + wordList.get(j).getParserParent() + "\t" + wordList.get(j).getParserRelation());
System.out.println();
}
}
} catch (Exception e) {
e.printStackTrace();
}
} 该用例首先将原始句子发出,返回得到一个ltml的结果。将结果中的单词合并放到一个wordlist中。同时建立一个空的ltml类,将wordlist内容填入ltml类里面。最后再次发回,得到结果。
C++
编译
C++版SDK采用编译工具CMake构建项目。 在编译C++版SDK前,需要安装CMake。 如果你是Windows用户,请下载CMake的二进制安装包; 如果你是Linux或者Mac OS的用户,可以通过源码的方式安装CMake。 当然,你也可以使用Linux的软件源安装CMake。
MSVC
在项目文件夹下新建一个名为build的文件夹。 使用CMake GUI,在source code中填入项目文件夹,在binaries中填入build文件夹。 然后Configure > Generate。
或者在命令行build路径下运行
cmake ..构建后得到ALL_BUILD、RUN_TESTS、ZERO_CHECK三个VC Project。 使用Visual Studio打开ALL_BUILD项目,构建项目后就可以编译获得名为ltpservice.lib的静态库。
在使用SDK时,只要在项目中链接ltpservice.lib, 并在include path中加入your/path/to/ltp-cloud-sdk/c++/include就可以编译。
Linux
使用linux环境编译C++版SDK,只需要在项目文件夹下运行
make编译例程,可以参考examples文件夹下的Makefile,一个例子如下:
g++ -o example1 -I../include -L../lib example1.cpp -lltpservice接口文档
LTPService类
LTPService.h位于__ltpService内;该类主要负责与服务器交互,并将返回结果以Ltml对象返回。
LTPService
- 功能:构造函数,初始化用户信息
- 参数:
参数名 参数描述 const std::string& authorization 用户验证信息,信息格式为:"email:token"
bool Analyze
- 功能:发送字符串类型待分析信息,得到服务器分析结果。
- 参数:
参数名 参数描述 const std::string& option 分析方式,分析的方式LTPOption.xxx。可参阅LTPOption类 const std::string& analyzeString 待分析的字串 LTML& ltml_out 保存分析结果,为一个LTML类 - 返回值:成功返回true,失败返回false
bool Analyze
- 功能:发送LTML类型待分析信息,得到服务器分析结果。也可以根据自己的需求完成部分中文信息处理,保存在LTML类里,让服务器帮你完成其他任务。
- 参数:
参数名 参数描述 const std::string& option 分析方式,分析的方式LTPOption.xxx。可参阅LTPOption类 const LTML& ltml_in 待分析的信息,为LTML类 LTML& ltml_out 保存分析结果,为一个LTML类 - 返回值:成功返回true,失败返回false
LTML类
LTML.h位于__ltpService内;LTML类提供XML操作方法,包括XML的生成,XML中信息的提取。该类是对返回的数据(XML串)进行解析的主要对象。
bool GetWords
- 功能:提取LTML分析结果
- 参数:
参数名 参数描述 std::vector<Word> &wordList 分析结果序列,保存在Word类里 int sentenceIdx 选择提取的句子序号 - 返回值:成功返回true,失败返回false
bool GetSentenceContent
- 功能:提取分句结果
- 参数:
参数名 参数描述 string &content 分析结果序列,保存在Word类里 paragraphIdx 选择提取的段落号 int sentenceIdx 选择提取的句子号 - 返回值:成功返回true,失败返回false
以下几个方法是向LTML对象写数据的方法。注意以下几个问题:
- 请保证调用以下方法的LTML对象为空的,或首先调用过ClearDOM方法,以保证LTML对象中数据一致;
- 输入的数据必须保证一致,例如,如果第一个词完成了词性标注,则其余词也须完成词性标注,因为LTML对象是根据第一个词或第一句话生成的note结点;
已经调用SetOver的LTML对象不允许调用以下方法,否则会抛异常;凡是由LTPService对象返回的Ltml对象都调用过SetOver方法;
bool AddSentence
- 功能:在LTML中写入句子。输入完成部分分析的单词序列
- 参数:
参数名 参数描述 const vector <Word>&wordList 插入的组成句子的单词序列。其中note结点是根据第一个sentence第一个词生成的,必须保证后面句子中的词与第一个词一致,否则会抛异常。 int paragraphId 选择插入句子的段落号 - 返回值:成功返回true,失败返回false
bool AddSentence
- 功能:在LTML中写入句子。输入尚未做分词的字串
- 参数:
参数名 参数描述 const std::string sentenceContent 插入的组成句子的单词序列。其中note结点是根据第一个sentence第一个词生成的,必须保证后面句子中的词与第一个词一致,否则会抛异常。 int paragraphId 选择插入句子的段落号 - 返回值:成功返回true,失败返回false
Word
该类型是对XML的Element进行的封装,任何的分析结果必须先取到Word,才能取到相当相应的分析数据。
| 函数名 | 返回值 |
|---|---|
| string GetWS() | 返回词的具体内容。失败时返回空 |
| int GetID() | 返回词的ID号 |
| string GetPOS() | 返回词的词性标注。失败时返回空 |
| string GetNE() | 返回词的命名实体识别结果。失败时返回空 |
| int GetParserParent() | 返回词义消歧的解释。失败时返回空依存句法分析的父亲结点ID号,结返回结果为一个大于等于-2(>= -2)的整数,失败时返回-3 |
| bool IsPredicate() | 检查该词是否是谓词。是返回true,否则返回false。 |
| bool GetSRLs (std::vector<SRL> &srls) | 如果该词是谓词;返回SRL类型的vector<SRL> |
SRL
SRL类型是对语义角色标注结果的一种抽象,主要包括语义角色标注类型(结果),开始词的ID号及结束词的ID号
| 选项名 | 含义述 |
|---|---|
| SRL.type | 公有String类型,语义角色标注类型(结果) |
| SRL.beg | 公有int类型,开始词的ID号 |
| SRL.end | 公有int类型,结束词的ID号 |
LTPOption
作为全局常量定义了分析方式类型
| 选项名 | 含义述 |
|---|---|
| LTPOption.WS | 分词 |
| LTPOption.POS | 词性标注 |
| LTPOption. NE | 命名实体识别 |
| LTPOption. PARSER | 依存句法分析 |
| LTPOption.SRL | 语义角色标注 |
示例程序
例一
发送string类型的分析对象,得到分析结果,并将结果按分词、ID、词性、命名实体、依存关系、词义消歧、语义角色标注的顺序输出。
using namespace ltp::service;
int main(){
LTPService ls("email:token");
LTML ltml;
if (!ls.Analyze(LTPOption.ALL,"我爱北京天安门。", ltml)) {
cerr<<"Authorization is denied!"<<endl;
exit(EXIT_FAILURE);
}
int sentNum = ltml.CountSentence();
for ( int i = 0; i<sentNum; ++i) {
string sentCont;
ltml.GetSentenceContent(sentCont, i);
cout<< sentCont <<endl;
vector<Word> wordList;
ltml.GetWords(wordList, i);
//按句子打印输出
for( vector<Word>::iterator iter = wordList.begin(); iter!= wordList.end(); ++iter ){
cout<<iter->GetWS()<<"\t"<<iter->GetID();
cout<<"\t"<<iter->GetPOS();
cout<<"\t"<<iter->GetNE();
cout<<"\t"<<iter->GetParserParent()<<"\t"<<iter->GetParserRelation();
cout<<endl;
if( iter->IsPredicate() ){
vector<SRL> srls;
iter->GetSRLs(srls);
for(vector<SRL>::iterator iter = srls.begin(); iter != srls.end(); ++iter){
cout<<"\t"<<iter->type
<<"\t"<<iter->beg
<<"\t"<<iter->end
<<endl;
}
}
}
}
return 0;
}该用例首先实例化一个新的Service Client对象,用户名和密码被保存在这个对象中。然后,client发起一个请求,并指明分析目标位分词。请求结果返回并保存在一个LTML对象中。
例二
将待分析数据保存在LTML类中,发送LTML类型的分析对象得到分析结果。用例首先进行分词,将所得的词按用户词表进行合并或拆分,并对其进行依存句法分析。本例中将“午夜”与“巴赛罗那”进行了合并。
using namespace ltp::service;
int main(){
LTPService ls("email:token");
LTML ltmlBeg;
try{
if(!ls.Analyze(LTPOption.WS, "午夜巴塞罗那是对爱情的一次诙谐、充满智慧、独具匠心的冥想。", ltmlBeg)) {
cerr<<"Authorization is denied!"<<endl;
exit(EXIT_FAILURE);
}
vector<Word> wordList;
ltmlBeg.GetWords(wordList, 0);
//输出分词结果
for( vector<Word>::iterator iter = wordList.begin(); iter!= wordList.end(); ++iter ) {
cout<<iter->GetID()<<"\t"<<iter->GetWS()<<endl;
}
cout<<endl;
//将“午夜”与“巴赛罗那”合并,其它的词不变
vector<Word> mergeList;
Word mergeWord;
mergeWord.SetWS(wordList.at(0).GetWS() + wordList.at(1).GetWS());
mergeList.push_back(mergeWord);
for (vector<Word>::iterator iter = wordList.begin()+2; iter != wordList.end(); ++iter)
{
Word others;
others.SetWS(iter->GetWS());
mergeList.push_back(others);
}
LTML ltmlSec;
ltmlSec.AddSentence(mergeList, 0);
ltmlSec.SetOver();
LTML ltmlOut;
ls.Analyze(LTPOption.PARSER, ltmlSec, ltmlOut);
//输出合并分词后PARSER结果
cout<<"merge and get parser results."<<endl;
vector<Word> outList;
ltmlOut.GetWords(outList,0);
for (vector<Word>::iterator iter = outList.begin(); iter != outList.end(); ++iter)
{
cout<<iter->GetID()<<"\t"<<iter->GetWS()<<"\t"<<iter->GetPOS()<<"\t"<<iter->GetParserParent()<<"\t"<<iter->GetParserRelation()<<endl;
}
cout<<endl;
}catch(exception& e){
std::cerr<<e.what();
}
return 0;
}该用例首先将原始句子发出,返回得到一个ltml的结果。将结果中的单词合并放到一个wordlist中。同时建立一个空的ltml类,将wordlist内容填入ltml类里面。最后再次发回,得到结果。
Python
安装module
如果你不希望把ltpservice安装在本地,你可以直接用
PYTHONPATH={PATH_TO_YOUR_PROJECT} python your_script.py
调用ltpservice。
如果你希望安装ltpservice,你可以用如下命令
[sudo] python setup.py install
安装ltpservice。
接口文档
LTPService类
位于`ltpservice.LTPService` 该类主要负责与服务器交互,并将返回结果以Ltml对象返回。
LTPService
- 功能:构造函数,初始化用户信息
- 参数:
参数名 参数描述 authorization 用户验证信息,信息格式为:"email:token" encoding 可选参数encoding设置字符编码,默认为utf-8,目前仅支持UTF-8及GBK,GB2312
Analyze
- 功能:发送字符串类型待分析信息,得到服务器分析结果
- 参数:
参数名 参数描述 input 分析内容,可以为string类型的字符串,也可以为由用户指定的待分析的LTML对象。 opt 分析方式包括:分词(LTPOption.WS),词性标注(LTPOption.POS),命名实体识别(LTPOption. NE),依存句法分析(LTPOption. PARSER),语义角色标注(LTPOption.SRL)。 - 返回值:返回分析结果,为一个LTML类
LTML类
LTML类位于ltpservice.LTML内; LTML类提供XML操作方法,包括XML的生成,XML中信息的提取。 该类是对返回的数据(XML串)进行解析的主要对象。
LTML
- 功能:构造函数,生成一个LTML类
- 参数:
参数名 参数描述 xmlstr 可选参数xmlstr为XML串,用于生成LTML对象;也可以缺省,生成空的LTML对象 encoding 可选参数encoding设置字符编码,默认为utf-8,目前仅支持UTF-8及GBK,GB2312
get_sentence
- 功能:get_sentence
- 参数:
参数名 参数描述 pid 选择提取的段落号 sid 选择提取的句子号 encoding 可选参数encoding设置字符编码,默认为utf-8,目前仅支持UTF-8及GBK,GB2312 - 返回值:返回中文分析结果序列,为str列表
count_paragraph
- 功能:计算分析结果中段落数。
- 返回值:返回分析结果中段落数
count_sentence
- 功能:计算LTML中的句子数量
- 参数:
参数名 参数描述 pid 可选参数,选择提取的段落号。当缺省时返回全篇的句子数量 - 返回值:返回句子数量
tostring
- 功能:将LTML转为字符串。
- 参数:
参数名 参数描述 encoding 可选参数encoding设置字符编码,默认为utf-8 - 返回值:返回转换生成的XML字符串
build_from_words
- 功能:向LTML对象写入完成一定分析内容的单词序列
- 参数:
参数名 参数描述 words 如果输入分词序列,words为一个str的列表,例如["我","爱","北京","天安门"]。如果输入词性标注序列,words为一个(str,str)的列表,例如[("我","p"),("爱","v"),("北京","ns"),("天安门","n")] encoding 可选参数encoding设置字符编码,默认为utf-8,目前仅支持UTF-8及GBK,GB2312
build
- 功能:向LTML对象写入一个未完成分词的待分析句子
- 参数:
参数名 参数描述 buffer 待分析句子 encoding 可选参数encoding设置字符编码,默认为可选参数encoding设置字符编码,默认为utf-8
LTPOption类
作为全局常量定义了分析方式类型
| 选项名 | 含义述 |
|---|---|
| LTPOption.WS | 分词 |
| LTPOption.POS | 词性标注 |
| LTPOption.NE | 命名实体识别 |
| LTPOption.PARSER | 依存句法分析 |
| LTPOption.SRL | 语义角色标注 |
| LTPOption.ALL | 全选 |
示例程序
例一
发送string类型的分析对象,得到分析结果
# -*- coding:utf8 -*-
import ltpservice
from account import email, token
client = ltpservice.LTPService("%s:%s" % (email, token))
result = client.analysis("我爱北京天安门。天安门上太阳升。", ltpservice.LTPOption.WS)
pid = 0
for sid in xrange(result.count_sentence(pid)):
print "|".join([word.encode("utf8") for word in result.get_words(pid, sid)])
该用例首先,import ltpservice这个package,然后实例化一个新的Service Client对象,用户名和密码被保存在这个对象中 。然后,client发起一个请求,并指明分析目标位分词。 请求结果返回并保存在一个LTML对象中。
例二
将待分析数据保存在LTML类中,发送LTML类型的分析对象得到分析结果
# -*- coding:utf8 -*-
import ltpservice
from account import email, token
client = ltpservice.LTPService("%s:%s" % (email, token))
ltml = ltpservice.LTML()
ltml.build_from_words(["我", "爱", "北京", "天安门"])
result = client.analysis(ltml, ltpservice.LTPOption.PARSER)
print result.tostring()
在上面的示例代码中,第2行import ltpservice这个package。 第3行实例化一个新的ltpservice对象,用户名和密码被保存在这个对象中。 第6行创建一个空的LTML类。 第7行通过word list构建这个类作为输入数据。 第9行将这个类作为传入参数发送给ltpservice分析。 第10行打印分析结果。
C#
编译
Visual Studio 编译:
第一步:添加引用的库函数:
右击你创建的工程的引用目录,点击添加引用后弹出对话框,在浏览页面中选中你要添加的动态链接库便可。
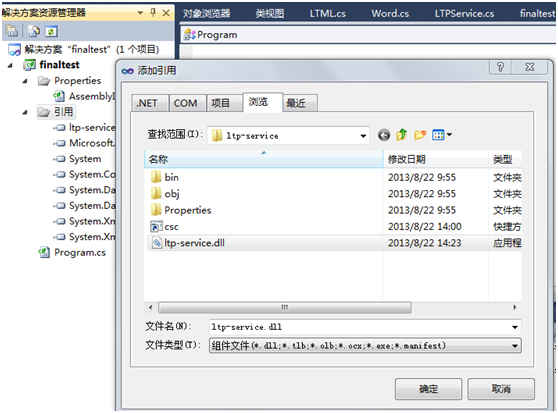
第二步:编译
在头部添加使用名空间:using ltp_service,即可顺利编译
命令行编译:
由于编译时需要调用动态链接库,所以执行下面命令
编译 :csc /reference:/…/ltp-service.dll /…/YouProgram.cs
运行 : YouProgram.exe
若用户想自己对源代码进行修改,自己生成.dll文件可以执行下面指令
csc /target:library /out:ltp-service.dll *.cs
接口文档
LTPService类
位于名空间ltp_service下。 该类主要负责与服务器交互,并将返回结果以Ltml对象返回。
LTPService
- 功能:构造函数,初始化用户信息
- 参数:
参数名 参数描述 String authorization 用户验证信息,信息格式为:"email:token"
LTML Analyze
- 功能:发送字符串类型待分析信息,得到服务器分析结果。
- 参数:
参数名 参数描述 String option 分析方式,分析的方式LTPOption.xxx。可参阅LTPOption类 String analyzeString 待分析的字串 - 返回值:返回分析结果,为一个LTML类
LTML Analyze
- 功能:发送LTML类型待分析信息,得到服务器分析结果。也可以根据自己的需求完成部分中文信息处理,保存在LTML类里,让服务器帮你完成其他任务。
- 参数:
参数名 参数描述 String option 分析方式,分析的方式LTPOption.xxx。可参阅LTPOption类 LTML ltmlIn 待分析的信息,为LTML类 - 返回值:返回分析结果,为一个LTML类
LTML类
位于名空间ltp_service 该类是对返回的数据(xml)进行解析的主要对象。
List<Word> GetWords
- 功能:提取LTML分析结果。
- 参数:
参数名 参数描述 int paragraphId (可缺省)选择提取的段落序号 int sentenceIdx 选择提取的句子序号(当段落参数缺省时为全篇中句子序号) - 返回值:提取的LTML分析结果。
String GetSentenceContent
- 功能:提取分句结果。
- 参数:
参数名 参数描述 int paragraphIdx (可缺省)选择提取的段落号针 int sentenceIdx 选择提取的句子号(当段落参数缺省时为全篇中句子序号) - 返回值:提取的分句结果
int CountSentence
- 功能:计算指定范围句子数
- 参数:
参数名 参数描述 int paragraphIdx (可缺省)选择提取的段落号(当缺省时则计算全篇的句子数量) - 返回值:选定范围的句子数量
以下几个方法是向LTML对象写数据的方法。注意以下几个问题:
- 请保证调用以下方法的LTML对象为空的,或首先调用过ClearDOM方法,以保证LTML对象中数据一致;
- 输入的数据必须保证一致,例如,如果第一个词完成了词性标注,则其余词也须完成词性标注,因为LTML对象是根据第一个词或第一句话生成的note结点;
已经调用SetOver的LTML对象不允许调用以下方法,否则会抛异常;凡是由LTPService对象返回的Ltml对象都调用过SetOver方法;
void AddSentence
- 功能:在LTML中写入句子。输入完成部分分析的单词序列。
- 参数:
参数名 参数描述 List<Word> wordList 插入的组成句子的单词序列。其中note结点是根据第一个sentence第一个词生成的,必须保证后面句子中的词与第一个词一致,否则会抛异常。 int paragraphId 选择插入句子的段落号
void AddSentence
- 功能:在LTML中写入句子。输入尚未做分词的字串
- 参数:
参数名 参数描述 String sentenceContent 插入的组成句子字串。 int paragraphId 选择插入句子的段落号
Word
该类型是对XML的Element进行的封装,任何的分析结果必须先取到Word,才能取到相当相应的分析数据。
| 函数名 | 返回值 |
|---|---|
| String GetWS() | 返回词的具体内容。失败时返回空 |
| int GetID() | 返回词的ID号 |
| String GetPOS() | 返回词的词性标注。失败时返回空 |
| String GetNE() | 返回词的命名实体识别结果。失败时返回空 |
| String GetWSD() | 返回词义消歧结果。失败时返回空 |
| int GetParserParent() | 返回词义消歧的解释。失败时返回空依存句法分析的父亲结点ID号,结返回结果为一个大于等于-2(>= -2)的整数,失败时返回-3 |
| bool IsPredicate() | 检查该词是否是谓词。是返回true,否则返回false。 |
| List<SRL> GetSRLs() | 如果该词是谓词;返回SRL类型的List<SRL> |
SRL
SRL类型是对语义角色标注结果的一种抽象,主要包括语义角色标注类型(结果),开始词的ID号及结束词的ID号
| 选项名 | 含义述 |
|---|---|
| SRL.strType | 公有String类型,语义角色标注类型(结果) |
| SRL.iBegin | 公有int类型,开始词的ID号 |
| SRL.iEnd | 公有int类型,结束词的ID号 |
LTMLOption
作为全局常量定义了分析方式类型
| 选项名 | 含义述 |
|---|---|
| LTPOption.WS | 分词 |
| LTPOption.POS | 词性标注 |
| LTPOption.NE | 命名实体识别 |
| LTPOption.WSD | 词义消歧 |
| LTPOption.PARSER | 依存句法分析 |
| LTPOption.SRL | 语义角色标注 |
示例程序
用例一
发送string类型的分析对象,得到分析结果。并将结果按分词、ID、词性、命名实体、依存关系、词义消歧、语义角色标注的顺序输出。
static void Main()
{
LTPService ltpService = new LTPService(strAuthorize);
String strSentence_new = "今天天气好晴朗,处处好风光。好听吗?";
LTML ltml = ltpService.Analyze(LTPOption.ALL, strSentence_new);
int sentNum = ltml.CountSentence();
for (int i = 0; i < sentNum; ++i)
{
string sentCont = ltml.GetSentenceContent(i);
Console.WriteLine(sentCont);
List wordList = ltml.GetWords(i);
foreach (Word curWord in wordList)
{
Console.Write(curWord.GetWS() + "\t" + curWord.GetID());
Console.Write("\t" + curWord.GetPOS());
Console.Write("\t" + curWord.GetNE());
Console.Write("\t" + curWord.GetParserParent() + "\t" + curWord.GetParserRelation());
Console.Write("\t" + curWord.GetWSD() + "\t" + curWord.GetWSDExplanation());
Console.WriteLine();
if (curWord.IsPredicate())
{
List srls = curWord.GetSRLs();
Console.WriteLine(srls.Count);
foreach (SRL srl in srls)
{
Console.WriteLine(srl.ToString());
}
}
}
}
}
该用例首先实例化一个新的Service Client对象,用户名和密码被保存在这个对象中。然后,client发起一个请求,并指明分析目标位分词。请求结果返回并保存在一个LTML对象中。
例二
将待分析数据保存在LTML类中,发送LTML类型的分析对象得到分析结果。用例首先进行分词,将所得的词按用户词表进行合并或拆分,并对其进行依存句法分析。 本例中将“午夜”与“巴赛罗那”进行了合并。
public static void Main() {
LTPService ls = new LTPService("email:token");
try {
LTML ltmlBeg = ls.Analyze(LTPOption.WS," 午夜巴塞罗那是对爱情的一次诙谐、充满智慧、独具匠心的冥想。");
LTML ltmlSec = new LTML();
int sentNum = ltmlBeg.CountSentence();
for(int i = 0; i < sentNum; ++i){
List<Word> wordList = ltmlBeg.GetWords(i);
foreach (Word curWord in wordList)
{
Console.WriteLine("\t" + curWord.GetID());
Console.WriteLine("\t" + curWord.GetWS());
Console.WriteLine();
}
// merge
List<Word> mergeList = new List<Word>();
Word mergeWord = new Word();
mergeWord.SetWS(wordList[0].GetWS()+wordList[1].GetWS());
mergeList.Add(mergeWord);
for(int j = 2; j < wordList.Count; ++j){
Word others = new Word();
others.SetWS(wordList[j].GetWS());
mergeList.Add(others);
}
ltmlSec.AddSentence(mergeList, 0);
}
ltmlSec.SetOver();
Console.WriteLine("\nmerge and get parser results.");
LTML ltmlOut = ls.Analyze(LTPOption.PARSER, ltmlSec);
for(int i = 0; i < sentNum; ++i){
List<Word> wordList = ltmlOut.GetWords(i);
foreach (Word curWord in wordList){
Console.WriteLine("\t" + curWord.GetID());
Console.WriteLine("\t" + curWord.GetWS());
Console.WriteLine("\t" + curWord.GetPOS());
Console.WriteLine("\t" + curWord.GetParserParent() + "\t" + curWord.GetParserRelation());
Console.WriteLine();
}
}
}
catch (Exception e)
{
Console.WriteLine(e.Message);
}
}
该用例首先将原始句子发出,返回得到一个ltml的结果。将结果中的单词合并放到一个wordlist中。同时建立一个空的ltml类,将wordlist内容填入ltml类里面。最后再次发回,得到结果。
Ruby
安装gem包
在Ruby目录下执行如下命令:
gem build ltpservice.gemspec
[sudo] gem install ltpservice-0.0.0.gem
安装完成后,可以用示例程序验证gem 安装的正确性。 方法是运行命令:
ruby test/example1.rb接口文档
LTPService类
位于ltpservice 包内 该类主要负责与服务器交互,并将返回结果以Ltml对象返回。
LTPService
- 功能:构造函数,初始化用户信息
- 参数:
参数名 参数描述 user 用户名 password 用户密码
Analyze
- 功能:发送字符串类型待分析信息,得到服务器分析结果
- 参数:
参数名 参数描述 input 分析内容,可以为string类型的字符串,也可以为由用户指定的待分析的LTML对象。 opt (可选参数)分析方式, 详细见下LTPOption encoding (可选参数)encoding设置字符编码,默认为utf-8,目前仅支持UTF-8及GBK,GB2312 - 返回值:返回分析结果,为一个LTML类
LTML类
LTML类位于ltpservice包内; LTML类提供XML操作方法,包括XML的生成,XML中信息的提取。 该类是对返回的数据(XML串)进行解析的主要对象。
LTML
- 功能:构造函数,生成一个LTML类
- 参数:
参数名 参数描述 xmlstr 可选参数xmlstr为XML串,用于生成LTML对象;也可以缺省,生成空的LTML对象
get_sentence
- 功能:get_sentence
- 参数:
参数名 参数描述 pid 选择提取的段落号 sid 选择提取的句子号 - 返回中文分析结果序列,为str数组里
count_paragraph
- 功能:计算分析结果中段落数。
- 返回值:返回分析结果中段落数
count_sentence
- 功能:计算LTML中的句子数量
- 参数:
参数名 参数描述 pid (可选参数),选择提取的段落号。当缺省时返回全篇的句子数量 - 返回值:返回句子数量
to_s
- 功能:将LTML转为字符串。
- 返回值:返回转换生成的XML字符串
build_from_words
- 功能:向LTML对象写入完成一定分析内容的单词序列
- 参数:
参数名 参数描述 words 输入分词序列,words为一个str的列表,例如[“我”,”爱”,”北京”,”天安门”]。 encoding (可选参数)encoding设置字符编码,默认为utf-8,目前仅支持UTF-8及GBK,GB2312
build
- 功能:向LTML对象写入一个未完成分词的待分析句子
- 参数:
参数名 参数描述 sentence 待分析句子 encoding (可选参数)encoding设置字符编码,默认为可选参数encoding设置字符编码,默认为utf-8
LTPOption
作为全局常量定义了分析方式类型
| 选项名 | 含义述 |
|---|---|
| LTPOption::WS | 分词 |
| LTPOption::POS | 词性标注 |
| LTPOption::NE | 命名实体识别 |
| LTPOption::PARSER | 依存句法分析 |
| LTPOption::SRL | 语义角色标注 |
| LTPOption::ALL | 全选 |
示例程序
例一
发送string类型的分析对象,得到分析结果
# encoding: UTF-8
require 'ltpservice'
client = LTPService.new('email', 'token')
ltml = LTML.new
ltml.build_from_words('我爱北京天安门', LTPOption::WS, 'UTF-8')
ltml_out=client.analyze(ltml)
pid=0
for sid in 0...ltml_out.count_sentence(pid)
ltml_out.get_words(pid,sid).each{ |word|
puts "#{word} "
}
puts "\n"
end首先,require ltpservice这个gem,然后实例化一个新的LTPService对象,用户名和密码被保存在这个对象中。 然后,client调用analyze()发起一个请求,并指明分析目标位分词。 请求结果返回并保存在一个LTML对象中。然后从该对象取出分析结果。
例二
将待分析数据保存在LTML类中,发送LTML类型的分析对象得到分析结果
# encoding: UTF-8
require 'ltpservice'
client = LTPService.new('email', 'token')
ltml = LTML.new
ltml.build_from_words(['我', '爱', '北京', '天安门'], 'UTF-8')
ltml_out=client.analyze(ltml)
pid=0
for sid in 0...ltml_out.count_sentence(pid)
ltml_out.get_words(pid,sid).each{ |word|
puts "#{word} "
}
puts "\n"
end首先,require ltpservice这个gem,然后实例化一个新的Service Client对象,用户名和密码被保存在这个对象中。然后建立一个空的ltml类,将句子内容填入ltml类里面。最后发送请求得到结果