English Introduction
A brief introduction of LTP-cloud and the service it provided
Language Technology Platform Cloud
LTP-Cloud (Language Technology Platform Cloud), is developed by the Research Center for Social Computing and Information Retrieval at Harbin Harbin Institute of Technology (HIT-SCIR). It is a Cloud based analysis infrastructure, which provides rich, scalable and accuracy natural language processing service. Modules integrated in LTP-cloud includes Chinese word segmentation, POS tagging, dependency parsing, named entity recognition, and semantic role labeling.
As a cloud-based service, LTP-cloud has the following features:
- Free Installation: user only needs to download the LTP-Cloud client source code, compile and run. The results can be obtained without calling a static library or download model file.
- Low Requirements on Hardware: LTP-Cloud client can be run on almost any hardware configuration of the computer. User doesn't need to buy a high-performance machine.
- Programming Language Free, Multiple Platform Supports: LTP Cloud API can be accessed from simple HTTP request, thus, cancealing the dependency of programming language.
Language Technology Platform
The Language Technology Platform (LTP), is an open-sourced Chinese natural language processing system developed in the Research Center for Social Computing and Information Retrieval, HIT. LTP has developed an XML-based natural language processing results expression, and on this basis provides a rich set of bottom-up, efficient, high-precision Chinese natural language processing modules including lexical, syntactic, semantic analysis and other five Chinese processing core technology.
LTP has obtained excellent results in serveral Chinese and international bake-offs. Especially it won the first place in the CoNLL 2009 international joint evaluation of syntactic and semantic analysis. LTP also provides well-documented web service, programming interface and visualization tools.
The academic version of LTP has been shared with more than 500 research institutions free of charge, Baidu, Tencent, Huawei, Kingsoft and other companies pay to use the commercial version of LTP. In 2010, LTP was awarded the highest award in Chinese Information Processing - "Weichang Qian Chinese Information Processing Science and Technology Award."
If your company or institute needs a series of high-performance Chinese natural language analysis toolkit to deal with large-scale data, or you want to lanch your study based on some low-level Chinese natural language processing modules, or you want to compare your own experimental results were with the state-of-the-art work, LTP may be your choice.
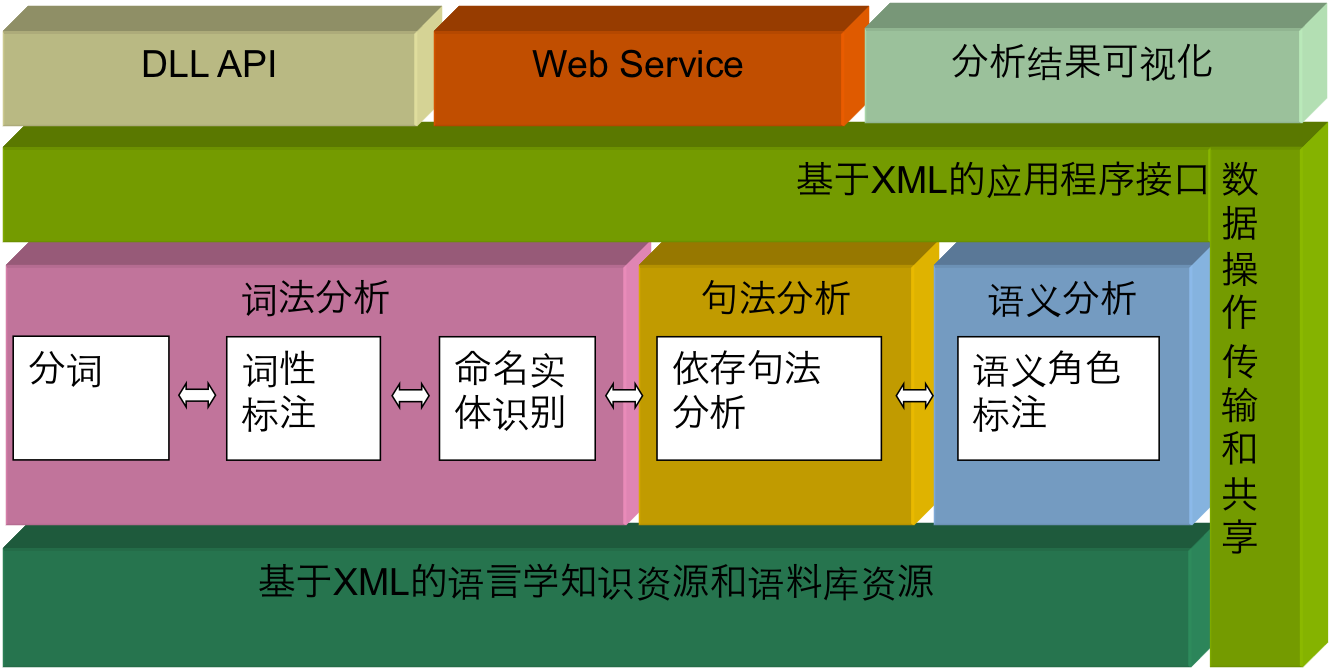
Language Technology Platform Architecture
Task Description
Why we need language analysis
Supposing your company has released a new mobile phone. The release of this new product brought mass reports and user feedback. Facing mess of the data, you may want to know
- What are the features that people mainly concern
- What's the review of the phone
- Who expressed the willingness to buy
Let the machine replace people to complete these analysis work is what natural language processing does.
What kind of language analysis we need
Chinese Word Segmentation (CWS)
Chinese word segmentation (CWS) is the task of segmenting Chinese sentence into word sequence. Since word is the basic language unit that carrying sense in Chinese, word segmentation is the initial step of information retrieval, text classification, sentiment analysis and many other Chinese natural language processing tasks.
Chinese word segmentation becomes a tough task because the combination of characters may introduce ambiguities. For example, for the following sentence:
国务院总理李克强调研上海外高桥时提出,支持上海积极探索新机制。国务院/ 总理/ 李克强/ 调研/ 上海/ 外高桥/ 时/ 提出/ ,/ 支持/ 上海/ 积极/ 探索/ 新/ 机制/ 。强调(emphasize) is a common word, system may fail to distinguish it from a Chinese name and give wrong result as follows:
国务院/ 总理/ 李克/ 强调/ 研/ 上海 …李克强.
Ambiguity is a major problem in segmentation task. LTP's word segment module is based on machine learning framework that is powerful to solve the ambiguity problem. Meanwhile, owing the dictionary strategies which incorporated in the model, new words information can be easily handled with sufficient materials.
Part-of-speech Tagging (POS)
Part-of-speech Tagging (POS) is the task of labeling each word in a sentence with its appropriate part of speech. We decide whether each word is a noun, verb, adjective, or whatever. The following sentence is an example of:
国务院/ni 总理/n 李克强/nh 调研/v 上海/ns 外高桥/ns 时/n 提出/v ,/wp 支持/v 上海/ns 积极/a 探索/v 新/a 机制/n 。/wpThe POS Tag of word as a generalization of the word, in speech recognition, parsing, information extraction tasks such an important role. For example, in the extraction "歌曲(songs)" of the related properties, we have a series of phrases:
儿童歌曲 欢快歌曲 各种歌曲 悲伤歌曲 ...[adjective]歌曲 [noun]歌曲 [pronouns]歌曲is more often not to describe attributes of the template.
The POS sets:The POS module of LTP uses the sets in "863", each of its meaning is listed in following table:
| Tag | Description | Example | Tag | Description | Example |
|---|---|---|---|---|---|
| a | adjective | 美丽 | ni | organization name | 保险公司 |
| b | other noun-modifier | 大型, 西式 | nl | location noun | 城郊 |
| c | conjunction | 和, 虽然 | ns | geographical name | 北京 |
| d | adverb | 很 | nt | temporal noun | 近日, 明代 |
| e | exclamation | 哎 | nz | other proper noun | 诺贝尔奖 |
| g | morpheme | 茨, 甥 | o | onomatopoeia | 哗啦 |
| h | prefix | 阿, 伪 | p | preposition | 在, 把 |
| i | idiom | 百花齐放 | q | quantity | 个 |
| j | abbreviation | 公检法 | r | pronoun | 我们 |
| k | suffix | 界, 率 | u | auxiliary | 的, 地 |
| m | number | 一, 第一 | v | verb | 跑, 学习 |
| n | general noun | 苹果 | wp | punctuation | ,。! |
| nd | direction noun | 右侧 | ws | foreign words | CPU |
| nh | person name | 杜甫, 汤姆 | x | non-lexeme | 萄, 翱 |
Named Entity Recognition (NER)
NER is the task to locate and identify the names of person, location, orgnization and other entities in a sequence of words in a sentence. As in the previous example, NER results are:
国务院 (organization name) 总理李克强 (person name) 调研上海外高桥 (location name) 时提出,支持上海 (location name) 积极探索新机制。 NER is important for mining entities in text, which can futher improve extracting events or mining information.
Types of named entity is usually determined by the task. LTP provides the most basic of the three entity type names, places, organization name recognition. Users can easily expanded the ner tags into a brand name of an entity type, software, names, etc.
Dependency Parsing (DP)
By analyzing the dependency relations between language components, dependency parsing reveals its syntactic structure. Intuitively, DP identifies "subject-verb", "adverbial" and other grammatical structure and analyzes the relationship between different components in a sentence. As the example above, the analysis result is:

From the analysis results, we can see that the head predicate in the sentence is "提出", the subject is "李克强" and proposed the object is "支持上海 ...", "调研... 时" is the time adverbial of "支持", "李克强" modifiers "国务院总理", the object of "支持" is "探索 新机制". With the above syntax analysis, we can more easily see that "提出者" is "李克强" instead of "上海" or "外高桥", even if they are nouns and the distance to "提出" is more close.
The annotation of dependency relations (total of 14) and their meanings are listed below:
| 关系类型 | Tag | Description | Example |
|---|---|---|---|
| 主谓关系 | SBV | subject-verb | 我送她一束花 (我 <-- 送) |
| 动宾关系 | VOB | 直接宾语,verb-object | 我送她一束花 (送 --> 花) |
| 间宾关系 | IOB | 间接宾语,indirect-object | 我送她一束花 (送 --> 她) |
| 前置宾语 | FOB | 前置宾语,fronting-object | 他什么书都读 (书 <-- 读) |
| 兼语 | DBL | double | 他请我吃饭 (请 --> 我) |
| 定中关系 | ATT | attribute | 红苹果 (红 <-- 苹果) |
| 状中结构 | ADV | adverbial | 非常美丽 (非常 <-- 美丽) |
| 动补结构 | CMP | complement | 做完了作业 (做 --> 完) |
| 并列关系 | COO | coordinate | 大山和大海 (大山 --> 大海) |
| 介宾关系 | POB | preposition-object | 在贸易区内 (在 --> 内) |
| 左附加关系 | LAD | left adjunct | 大山和大海 (和 <-- 大海) |
| 右附加关系 | RAD | right adjunct | 孩子们 (孩子 --> 们) |
| 独立结构 | IS | independent structure | 两个单句在结构上彼此独立 |
| 核心关系 | HED | head | 指整个句子的核心 |
Semantic Role Labeling (SRL)
SRL is a shallow semantic analysis technology to mark some phrases in a sentence as arguments of a given predicate, such as agent, patient, time and location. SRL can contribute to question answering system, information extraction and machine translation applications. For the above example, the SRL results are:

There are three predicates提出, 调研and探索for example, 探索,积极 is the way (generally expressed by ADV), while 新机制 is its patient (generally expressed by A1).
There are six kinds of the core of the semantic role from A0 to A5, A0 usually indicates the action agent, A1 is usually the impact of that action, A2-5 will be different according to different verb semantic meaning. The remaining 15 semantic roles are the additional semantic roles, such as LOC indicates locations, TMP represents time. Additional semantic roles are listed below:
| Annotation | Description |
| ADV | adverbial, default tag ( 附加的,默认标记 ) |
| BNE | beneficiary ( 受益人 ) |
| CND | condition ( 条件 ) |
| DIR | direction ( 方向 ) |
| DGR | degree ( 程度 ) |
| EXT | extent ( 扩展 ) |
| FRQ | frequency ( 频率 ) |
| LOC | locative ( 地点 ) |
| MNR | manner ( 方式 ) |
| PRP | purpose or reason ( 目的或原因 ) |
| TMP | temporal ( 时间 ) |
| TPC | topic ( 主题 ) |
| CRD | coordinated arguments ( 并列参数 ) |
| PRD | predicate ( 谓语动词 ) |
| PSR | possessor ( 持有者 ) |
| PSE | possessee ( 被持有 ) |
Semantic Dependency Parsing (SDP)
Given a complete sentence, semantic dependency parsing (SDP) aims at determining all the word pairs related to each other semantically and assigning specific predefined semantic relations, which is a projective tree structure now and will be expanded to directed acyclic graphs. Semantic dependency analysis represents the meaning of sentences by a collection of dependency word pairs and their corresponding relations. This procedure survives from syntactic variation. Here are three sentences:
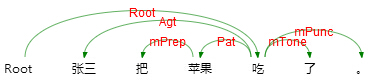
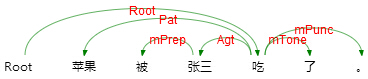

Their syntactic structures are distinct, while the same meaning is hidden behind these sentences. i.e. eat<he, apple>.
SDP is not influenced by syntactic structures which makes it focus on the real semantics of sentences. Here is an example illustrating the parsing results of DP and SDP respectively.
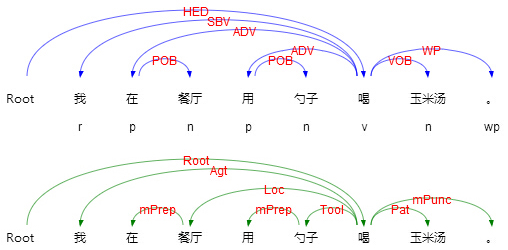
From the above comparison, we can conclude two points, the first one is syntactic dependencies put emphasis on non-entity words for their roles in partitioning the sentence structures. The second one is that the totally different dependency relations make SDP could represent the detail semantics. SDP can be used to answer the questions raised from the sentences, such as all the Wh-Questions. However, DP could not.
We classify the semantic relations into three categories, i.e. main semantic roles, each one of them has a corresponding reverse relation and a nested relation, event relations and semantic markers. Click here for the details of the Chinese semantic dependency scheme. Next, we list the semantic relations and make each one a simple explanation.
| 关系类型 | Tag | Description | Example |
|---|---|---|---|
| 施事关系 | Agt | Agent | 我送她一束花 (我 <-- 送) |
| 当事关系 | Exp | Experiencer | 我跑得快 (跑 --> 我) |
| 感事关系 | Aft | Affection | 我思念家乡 (思念 --> 我) |
| 领事关系 | Poss | Possessor | 他有一本好读 (他 <-- 有) |
| 受事关系 | Pat | Patient | 他打了小明 (打 --> 小明) |
| 客事关系 | Cont | Content | 他听到鞭炮声 (听 --> 鞭炮声) |
| 成事关系 | Prod | Product | 他写了本小说 (写 --> 小说) |
| 源事关系 | Orig | Origin | 我军缴获敌人四辆坦克 (缴获 --> 坦克) |
| 涉事关系 | Datv | Dative | 他告诉我个秘密 ( 告诉 --> 我 ) |
| 比较角色 | Comp | Comitative | 他成绩比我好 (他 --> 我) |
| 属事角色 | Belg | Belongings | 老赵有俩女儿 (老赵 <-- 有) |
| 类事角色 | Clas | Classification | 他是中学生 (是 --> 中学生) |
| 依据角色 | Accd | According | 本庭依法宣判 (依法 <-- 宣判) |
| 缘故角色 | Reas | Reason | 他在愁女儿婚事 (愁 --> 婚事) |
| 意图角色 | Int | Intention | 为了金牌他拼命努力 (金牌 <-- 努力) |
| 结局角色 | Cons | Consequence | 他跑了满头大汗 (跑 --> 满头大汗) |
| 方式角色 | Mann | Manner | 球慢慢滚进空门 (慢慢 <-- 滚) |
| 工具角色 | Tool | Tool | 她用砂锅熬粥 (砂锅 <-- 熬粥) |
| 材料角色 | Malt | Material | 她用小米熬粥 (小米 <-- 熬粥) |
| 时间角色 | Time | Time | 唐朝有个李白 (唐朝 <-- 有) |
| 空间角色 | Loc | Location | 这房子朝南 (朝 --> 南) |
| 历程角色 | Proc | Process | 火车正在过长江大桥 (过 --> 大桥) |
| 趋向角色 | Dir | Direction | 部队奔向南方 (奔 --> 南) |
| 范围角色 | Sco | Scope | 产品应该比质量 (比 --> 质量) |
| 数量角色 | Quan | Quantity | 一年有365天 (有 --> 天) |
| 数量数组 | Qp | Quantity-phrase | 三本书 (三 --> 本) |
| 频率角色 | Freq | Frequency | 他每天看书 (每天 <-- 看) |
| 顺序角色 | Seq | Sequence | 他跑第一 (跑 --> 第一) |
| 描写角色 | Desc(Feat) | Description | 他长得胖 (长 --> 胖) |
| 宿主角色 | Host | Host | 住房面积 (住房 <-- 面积) |
| 名字修饰角色 | Nmod | Name-modifier | 果戈里大街 (果戈里 <-- 大街) |
| 时间修饰角色 | Tmod | Time-modifier | 星期一上午 (星期一 <-- 上午) |
| 反角色 | r + main role | 打篮球的小姑娘 (打篮球 <-- 姑娘) | |
| 嵌套角色 | d + main role | 爷爷看见孙子在跑 (看见 --> 跑) | |
| 并列关系 | eCoo | event Coordination | 我喜欢唱歌和跳舞 (唱歌 --> 跳舞) |
| 选择关系 | eSelt | event Selection | 您是喝茶还是喝咖啡 (茶 --> 咖啡) |
| 等同关系 | eEqu | event Equivalent | 他们三个人一起走 (他们 --> 三个人) |
| 先行关系 | ePrec | event Precedent | 首先,先 |
| 顺承关系 | eSucc | event Successor | 随后,然后 |
| 递进关系 | eProg | event Progression | 况且,并且 |
| 转折关系 | eAdvt | event adversative | 却,然而 |
| 原因关系 | eCau | event Cause | 因为,既然 |
| 结果关系 | eResu | event Result | 因此,以致 |
| 推论关系 | eInf | event Result | 才,则 |
| 条件关系 | eCond | event Condition | 只要,除非 |
| 假设关系 | eSupp | event Supposition | 如果,要是 |
| 让步关系 | eConc | event Concession | 纵使,哪怕 |
| 手段关系 | eMetd | event Method | |
| 目的关系 | ePurp | event Purpose | 为了,以便 |
| 割舍关系 | eAban | event Abandonment | 与其,也不 |
| 选取关系 | ePref | event Preference | 不如,宁愿 |
| 总括关系 | eSum | event Summary | 总而言之 |
| 分叙关系 | eRect | event Recount | 例如,比方说 |
| 连词标记 | mConj | Recount Marker | 和,或 |
| 的字标记 | mAux | Auxiliary | 的,地,得 |
| 介词标记 | mPrep | Preposition | 把,被 |
| 语气标记 | mTone | Tone | 吗,呢 |
| 时间标记 | mTime | Time | 才,曾经 |
| 范围标记 | mRang | Range | 都,到处 |
| 程度标记 | mDegr | Degree | 很,稍微 |
| 频率标记 | mFreq | Frequency Marker | 再,常常 |
| 趋向标记 | mDir | Direction Marker | 上去,下来 |
| 插入语标记 | mPars | Parenthesis Marker | 总的来说,众所周知 |
| 否定标记 | mNeg | Negation Marker | 不,没,未 |
| 情态标记 | mMod | Modal Marker | 幸亏,会,能 |
| 标点标记 | mPunc | Repetition Marker | ,。! |
| 重复标记 | mPept | Repetition Marker | 走啊走 (走 --> 走) |
| 多数标记 | mMaj | Majority Marker | 们,等 |
| 实词虚化标记 | mVain | Vain Marker | |
| 离合标记 | mSepa | Seperation Marker | 吃了个饭 (吃 --> 饭) 洗了个澡 (洗 --> 澡) |
| 根节点 | Root | Root | 全句核心节点 |
Technique Summary and Performance
Chinese Word Segmentation (CWS)
Chinese word segmentation is the task of segmenting Chinese sentence into word sequence. Since Chinese word is the minimum unit that carrying sense, Chinese word segmentation became the initial step in many Chinese NLP tasks includeing Information Retrieve, Text classification, Sentiment Analysis.
Owing to the fundamental position of Chinese word segmentation, many studies have been conducted on this task. There are two general types of Chinese word segmentation methods. The first is lexicon matching methods and the second is machine learning based methods. Word segmentation model in LTP combines this two methods. The algorithm used in this model can both benifit from the disambiguity power of statistical machine learning model and widely covered lexicon.
In LTP, the word segmentation problems is modeled as character-based sequence labeling problem. For a given input sentence, the model tags each character with a tag which identifies word boundary.
Meanwhile, in order to improve the performance on the Internet text, especially the micro-blog, the following optimization strategies are incorporated into our word segmentation module:
- a special word like English word and URI are recognized by rules
- spaces and other natural annotated clues are used to help segmenting word
- lexicon information in compiled into statistical model
- mutual information, accessory variety collected from large scale unlabeled data is taken into consideration.
The performance of word segmentation module on People's Daily test sets is shown below:
- Accuracy
- Runtime memory:119m
- Speed:176.91k/s
- Second place in CLP 2012 Bakeoff Task 1: Chinese Word Segmentation on MicroBlog Corpora.
| P | R | F | |
| Development set | 0.973152 | 0.972430 | 0.972791 |
| Test set | 0.972316 | 0.970354 | 0.972433 |
Part-of-speech Tagging (POS)
The same as word segmentation module, POS Tagging can also be modeled as a sequence of labeling problem that labels each word a POS Tag. The tag set we employ in LTP is the Peking University tag set.
The performance of POS module on People's Daily test sets is shown below:
- Settings of Corpus: People's Daily corpus from February to June in 1998 is set as training data (the remaining 10% of data as a development set). The data in January is set as the test data.
- Accuracy:
P Development set 0.979621 Test set 0.978337 - Runtime memory:291m
- Speed:106.14k/s
Named Entity Recognition (NER)
The same with word segmentation module, the NER task is modeled as a sequence of labeling task based on word. For input sentence word sequence, the module tag each word in the sentence a named entity identification and entity class tag. LTP support recognize the names of persons, organizations, locations.
the performance is shown below:
- Settings of corpus: People's Daily in January 1998 to do the training (the remained 10% of data as a development set), 6 months ago 10,000 to do the test as training data.
- Accuracy
P R F Development set 0.924149 0.909323 Test set 0.939552 0.936372 - Runtime memory:21m
Dependency Parsing (DP)
Graph-based dependency parsing method is first proposed by the McDonald, he detrive it as the problem to find maximum spanning tree in a graph(Maximum Spanning Tree) .
In dependency parsing module, LTP realized
- first order decoding algorithm(1o)
- second-order decoding alogrithm incorporating sibling (2o-sib)
- second-order decoding alogrithm incorporating sibling and grandson (2o-carreras)
In the LDC data sets, the three different decoding performance is in the following table.
| model | 1o | 2o-sib | 2o-carreras | |||
|---|---|---|---|---|---|---|
| Uas | Las | Uas | Las | Uas | Las | |
| Dev | 0.8190 | 0.7893 | 0.8501 | 0.8213 | 0.8582 | 0.8294 |
| Test | 0.8118 | 0.7813 | 0.8421 | 0.8106 | 0.8447 | 0.8138 |
| Speed | 49.4 sent./s | 9.4 sent./s | 3.3 sent./s | |||
| Mem. | 0.825g | 1.3g | 1.6g |
- Ranked the second and third on SANCL 2012 Internet data dependency parsing evaluation
- Ranked third in Chinese dependency parsing on CoNLL 2009 evaluation of syntactic and semantic dependency parsing
Semantic Role Labeling (SRL)
In LTP, we divide SRL into two sub-tasks. Fist is the predicate identification and second is argument identification and classification. For the identification and classification of argument, we treat it as a joint mission, the "non-argument" and the "argument". In SRL system, we introduce the the L1 regular to the maximum entropy model which result in feature dimensions reduce to 1/40 of original one. It greatly improve the memory performance, and enhance the prediction speed. Meanwhile, in order to ensure annotation results meet certain constraints, the system adds post-processing.
In CoNLL 2009 evaluation data set, experiment result using automatic POS tags and syntax information in LTP is shown below.
| Precision | Recall | F-Score | Speed | Mem. |
|---|---|---|---|---|
| 0.8444 | 0.7234 | 0.7792 | 41.1 sent./s | 94M(PI+AIC) |
- First place in CoNLL-2009 Shared Task: Syntactic and Semantic Dependencies in Multiple Languages joint mission.