技术博客
有关语言云的更新、应用以及其他
使用语言云分析微博用户饮食习惯
2014-03-24 by bren
饮食习惯分析
饮食习惯分析属于传统社会学范畴内的问题。但我们知道,无论使用问卷调查,还是通过调研各种食品消耗量来进行饮食习惯分析,都是很耗时耗力且昂贵的。 而另一方面,比如微博这样的社会媒体上,又存在着大量诸如“我今天去吃麻辣烫”这样反映用户真实饮食行为的文本,并且通常你还可以看到这个人的性别、地区、发微博时间等信息。 所以,我们很容易联想到,用微博等社会媒体上的数据,加上自然语言处理工具,你可以以很低的成本,进行饮食习惯的挖掘和分析,且很可能获得更真实有效的结果。
我们所提到的饮食习惯分析,也只是一个抛砖引玉,你完全可以进行阅读习惯分析、某种商品的消费行为分析等等。
步骤
下面就介绍用语言云工具进行微博饮食习惯分析的步骤:
Step 1 获得微博数据
新浪微博的快速发展和API的完善,使得微博数据的获取并不困难。 您可以选择利用新浪API获得数据,自己爬取数据,或是通过数据堂等方式获得微博数据。 微博数据,除了微博本身的内容,还需要关注的是微博发布的时间,以及发微博的用户的性别、地区等信息,这样我们才可以进行更多基于不同维度的饮食习惯分析。
微博数据信息示例:

到我们的语言云官网(http://www.ltp-cloud.com/)阅读协议进行注册。
我们提供了分词、词性标注、依存句法分析、命名实体识别、语义角色标注在内的一系列工具,您在一次需求时可能并不会用到所有这些服务,您可以通过阅读简介(http://www.ltp-cloud.com/intro/)并结合您的任务目标了解和确定您所需要的具体服务。
像我们这次要进行的微博饮食分析,就需要用到语言云所提供的分词、词性标注和依存句法分析功能。
Step 3 用语言云处理文本
在有了微博数据,并获得了语言云的使用权限以后,我们就可以利用语言工具处理微博文本了。
在微博饮食分析中,我们需要用到分词、词性标注和依存句法分析。当研究一条微博判断是否发生饮食行为时,我们可以对微博内容的分词结果用这样一条规则:用含词语“吃”+与“吃”相关的句法关系为VOB(动宾关系)+“吃”的宾语为名词这三个条件来过滤。如果符合这个有三个条件的规则,则可以判定为发生了饮食行为,且提取出来的“吃”的宾语就是饮食行为涉及的食品。
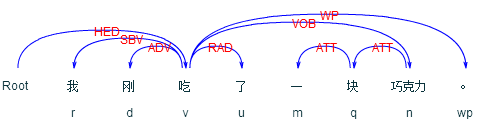
比如对“我刚吃了一块巧克力”这句话,用语言云进行分析可得结果:
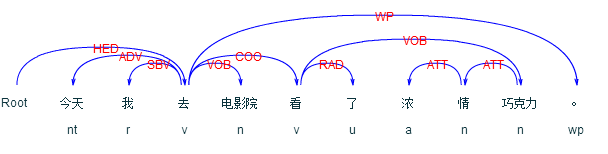
而对前文提到的例子“今天我去电影院看了浓情巧克力。”的分析结果则为:
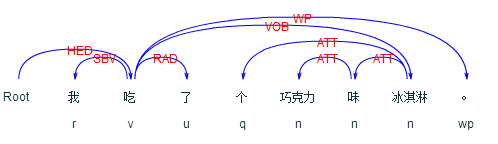
再比如像“我吃了个巧克力味冰淇淋。”这个句子,在传统的基于关键词匹配的方法中,会导致“巧克力”和“冰淇淋”各算一次,但实际上谈到的是吃冰淇淋,并不是吃巧克力。通过语言云分析,可以得到结果:
例如,使用Python语言以GET方式调用REST API代码示例如下:
# -*- coding:utf8 -*-
import urllib2
if __name__ == '__main__':
url_get_base = "http://api.ltp-cloud.com/analysis/?"
api_key = '' #注册语言后获得的认证标识
text = '' #待分析文本
format = '' #指定结果格式类型
pattern = '' #指定分析模式
result = urllib2.urlopen("%sapi_key=%s&text=%s&format=%s&pattern=%s" % (url_get_base,api_key,text,format,pattern))
content = result.read().strip()
print content
你可以选择获得xml格式的结果,然后通过调用一些python解析xml的模块,来解析xml结果,并匹配我们设定的规则的三个条件,以提取涉及饮食行为的微博中提到的食品。
Step 4 统计分析
已经有了从微博文本中用规则分析出的关于饮食习惯的词语,接下来只需要再根据不同的维度,如发微博时间、用户性别、地区等进行统计分析,就可以获得关于微博饮食习惯的结果。
比如一个北京女孩晚上发了一条微博“我去吃烤鸭了。”那么按照我们上面的分析已经能够识别出这是一次饮食行为,且吃的内容是“烤鸭”,就可以把这次吃“烤鸭”与时间“晚上”,性别“女”,地区“北京”对应起来。
然后可以按照一定的规则比如选取数量最多的或是计算互信息值等方式选取每个维度有代表性的食品作为特色饮食习惯的反映。
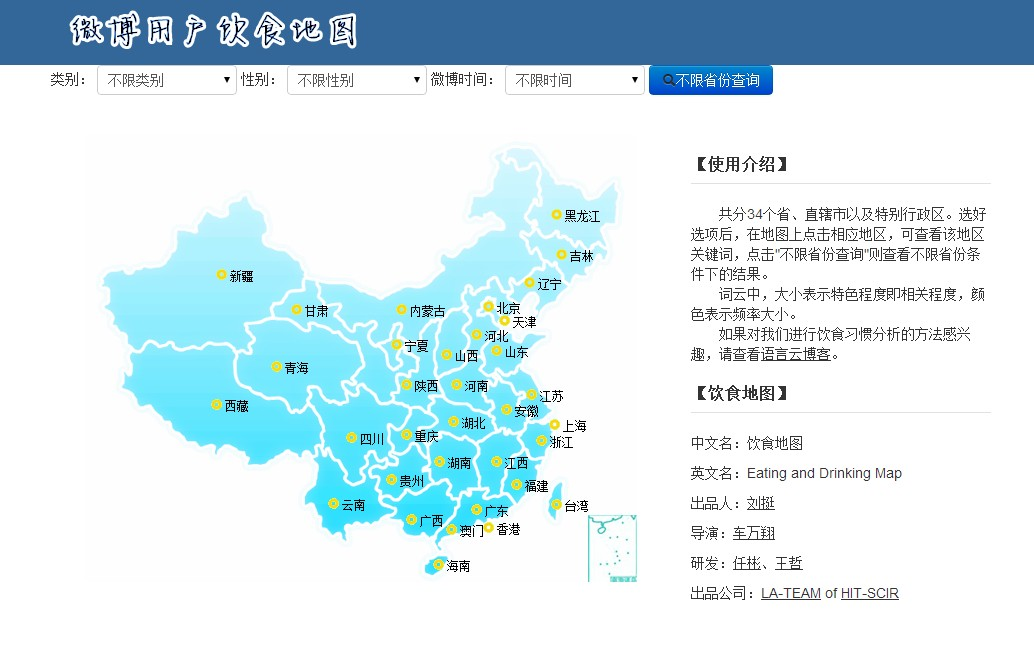
比如我们实现的关于性别、微博时间、地区等维度的统计和查询:
你还可以把结果用一定的可视化手段,比如“词云”的方式予以展现。如女性的特色饮食习惯用“词云”展现:



比如北京人晚上喜欢吃的食品:


结语
听了上面的例子,是不是已经大致了解怎样语言云能帮助您做什么了?
我们的语言云就是希望这样提供一系列成熟、完善的服务,让您能方便、快捷地能够使用自然语言分析的结果,并在此之上开展研究和应用,获得更多有趣、有用的结论!如果您有基于语言云的研究和应用,也欢迎告诉我们,期待看到您的创作!